2024-11-19
Relationship Between Memory and Data Structures
So far we've been talking about the introduction to data structures and now we’ll be talking about memory.
But we’ve to answer these questions first: why is memory so important at this point? Isn’t it related to hardware? When we’re programming and creating, why is it important to take the memory into account? Well these are good questions and actually we can spend a lot of time trying to explain why. The most simple answer is: because we need to take care about the resources involved in the project. When we talk about resources we’re talking about CPU, Processing and Memory (and maybe other resources). That means that if we create programs with a high resource consumption the project owners can end up investing a lot of money in those physical resources.
So when we create algorithms or use data structures to create a solution to a problem, we’ve to monitor, test and know what’s the real cost of our solutions to that problem and what’s the best possible solution for it (the optimal one). So yes, we are talking a bit about hardware things here, but we’ll see it with the eyes of a software developer not from the hardware specialist perspective.
Memory is an extense topic and we can spend a lot of time talking about the theoretical knowledge that it involves, so for now we just want to do practical examples and have the right amount of knowledge from software developer's perspective
Bits and Bytes
Bits and bytes are both units of data, but what is the actual difference between them? One byte is equivalent to eight bits. A bit is considered to be the smallest unit of data measurement. The bit represents a logical state with one of two possible values. These values are most commonly represented as either "1" or "0"
Bit == 1
Bytes == 00000001
Binary Numbers
Ok so far we’re clear about the differences. This tends to confuse newbies in programming (I was also confused in my beginnings) but what we need to understand at this point is that bits and bytes are “nothing” without a conversión. Let me explain, if we have a variable called my_number and I’d assign the number 3 to it, now we have to storage that value (3) in someplace of the memory to use it later while the program executes
So what we need to do is to convert that Integer 3 into a Binary Number (yes we’ve to use a formula to do that, but that’s not part of the post right now, but you can see more info here), and the result will be 00000011 (an 8-bit Integer), let’s check this webpage who helps us to do this kind of conversions: https://www.rapidtables.com/convert/number/binary-to-decimal.html
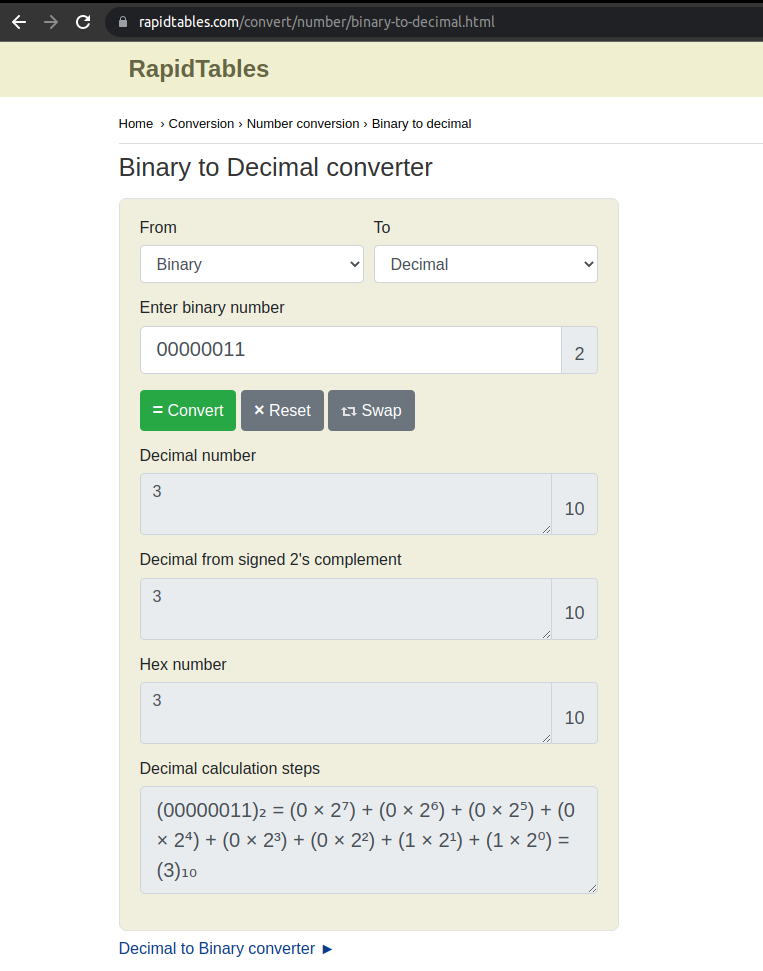
And also you can do the conversión swapping the number to convert
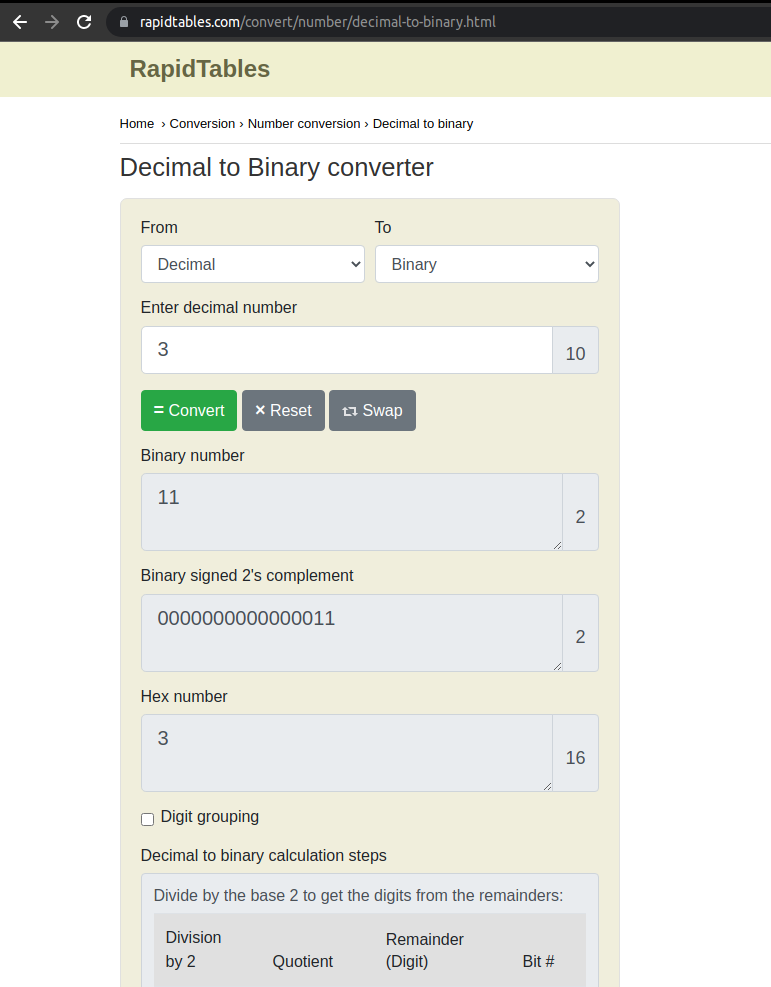
In this last table you’ll see the output of the binary number, that is “11”, this is because the zeros are omitted in the output
I know this is hard to get at the first time, but as I mentioned before the important thing to remember now is that we have to convert the data types we’ve seen so far in Ruby like: Numbers, Strings, Arrays and so on into Binary Numbers. Actually we don’t do that, our machine do that for us, but this is one of the construction block to understand better why we’ll need to optimize our solutions represented by algorithms
Once we have more clear the differences between bits and bytes we can see more in detail memory with an example. We’ll be working with 4 different variables.
- var_a = 0
- var_b = 1
- var_c = 2
- var_d = 3
In the last section we learnt that we have to convert values assigned to a variable into Binary Numbers (8-bit integer), so, the results we have once we do that are these:
- var_a = 0 ⇒ 00000000
- var_b = 1 ⇒ 00000001
- var_c = 2 ⇒ 00000010
- var_d = 3 ⇒ 00000011
Memory slots & Memory addresses
Now we want to simulate how a memory works internally. The first thing we have to take in mind is that memory is something finite not infinite and is because of that we have to take care about the optimization of our algorithms.
Second thing is that we have something (that we can) call memory slots and we can represent it as a table with its own internal spaces, and each internal space is represented by a memory address, in this case the numbers we give inside the table to each space: from zero to 15
0 | 1 | 2 | 3
4 | 5 | 6 | 7
8 | 9 | 10 | 11
12 | 13 | 14 | 15
4 | 5 | 6 | 7
8 | 9 | 10 | 11
12 | 13 | 14 | 15
Now let’s simulate how we can store our 4 variables in these memory slots. Given the fact that we already have the binary numbers (zeros and ones) we can store them inside each memory slot.
0 ⇒ In use | 1 ⇒ In use | 2 ⇒ In use | 3 ⇒ In use
4 ⇒ In use | 5 ⇒ 00000000 | 6 ⇒ 00000001 | 7 ⇒ 00000010
8 ⇒ 00000011 | 9 ⇒ free | 10 ⇒ free | 11 ⇒ free
12 ⇒ free | 13 ⇒ free | 14 ⇒ free | 15 ⇒ free
4 ⇒ In use | 5 ⇒ 00000000 | 6 ⇒ 00000001 | 7 ⇒ 00000010
8 ⇒ 00000011 | 9 ⇒ free | 10 ⇒ free | 11 ⇒ free
12 ⇒ free | 13 ⇒ free | 14 ⇒ free | 15 ⇒ free
What we have now is
- a memory address associated with a binary number. For instance address 8 is associated with 00000011
- a binary number associated with an integer. For instance 00000011 is associated with 3
- an integer associated with a variable 3 is associated with var_d
Things to note here:
- - All of these conversions are made by a computer at speed lightning
- - We didn't fill the first memory slots/addresses (intentionally) because we can say that they’re already in use (storing other data)
- - We didn't fill the last memory slots/addresses (intentionally) because we can say that they’re free for use (to store new data)
In computing, a memory address is a reference to a specific memory location used at various levels by software and hardware. Memory addresses are fixed-length sequences of digits conventionally displayed and manipulated as unsigned integers.
Such numerical semantic bases itself upon features of CPU (such as the instruction pointer and incremental address registers), as well upon use of the memory like an array endorsed by various programming languages. More info about memory address here
32 bit integer
Now let’s do a more realistic approach to memory usage. So far we’ve been working with 8-bit integers (like 00000001 or 00000010)
To work with 32-bits is almost the same, we’ve just to add zeros in the memory slots until we reach the 32-bits number. Let me explain with an example. We have just this variable
- var_d = 3 ⇒ 00000011 (8-bit integer)
- var_d = 3 ⇒ 00000000 00000000 00000000 00000011 (32-bit integer)
The question now is how we save this data inside our memory slots? Each memory slot can just save an 8-bit integer, so we need to use more memory slots to save the number 3 converted to a 32-bit integer just like this
0 ⇒ In use | 1 ⇒ In use | 2 ⇒ In use | 3 ⇒ In use
4 ⇒ In use | 5 ⇒ In use | 6 ⇒ In use | 7 ⇒ In use
8 ⇒ In use | 9 ⇒ 00000011 | 10 ⇒ 00000000 | 11 ⇒ 00000000
12 ⇒ 00000000 | 13 ⇒ free | 14 ⇒ free | 15 ⇒ free
4 ⇒ In use | 5 ⇒ In use | 6 ⇒ In use | 7 ⇒ In use
8 ⇒ In use | 9 ⇒ 00000011 | 10 ⇒ 00000000 | 11 ⇒ 00000000
12 ⇒ 00000000 | 13 ⇒ free | 14 ⇒ free | 15 ⇒ free
As we can see we’re now storing just the value of 3 converted to a 32-bit integer and we’ve assigned it to the addresses: 9, 10, 11, and 12. The first address contains the 8-bit integer and the rest of them are filled with zeros. That’s the way it works
64-bit Integer
What happens if we want to save in a 64-bit integer? Let's do it
- var_d = 3 ⇒ 00000011 (8-bit integer)
- var_d = 3 ⇒ 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000011 (64-bit integer)
Now we’ve just to fill more memory slots like so
0 ⇒ In use | 1 ⇒ In use | 2 ⇒ In use | 3 ⇒ In use
4 ⇒ In use | 5 ⇒ In use | 6 ⇒ In use | 7 ⇒ In use
8 ⇒ In use | 9 ⇒ 00000011 | 10 ⇒ 00000000 | 11 ⇒ 00000000
12 ⇒ 00000000 | 13 ⇒ 00000000 | 14 ⇒ 00000000 | 15 ⇒ 00000000
16 ⇒ 00000000 | 17 ⇒ free | 18 ⇒ free | 19 ⇒ free
4 ⇒ In use | 5 ⇒ In use | 6 ⇒ In use | 7 ⇒ In use
8 ⇒ In use | 9 ⇒ 00000011 | 10 ⇒ 00000000 | 11 ⇒ 00000000
12 ⇒ 00000000 | 13 ⇒ 00000000 | 14 ⇒ 00000000 | 15 ⇒ 00000000
16 ⇒ 00000000 | 17 ⇒ free | 18 ⇒ free | 19 ⇒ free
Note: remember that all of this is a very high level explanation, but an easy way to understand the basics about memory.
Pointers
So far we have declared directly the values we need to store in each memory slot. Sometimes we have just to retrieve information stored in other memory slots. What we need to do is to point to the address/addresses where the data is stored. It’s simple like that. Let’s see an example
0 ⇒ In use | 1 ⇒ In use | 2 ⇒ In use | 3 ⇒ In use
4 ⇒ In use | 5 ⇒ In use | 6 ⇒ In use | 7 ⇒ In use
8 ⇒ In use | 9 ⇒ 00000011 | 10 ⇒ 00000000 | 11 ⇒ 00000000
12 ⇒ 00000000 | 13 ⇒ 00000000 | 14 ⇒ 00000000 | 15 ⇒ 00000000
16 ⇒ 00000000 | 17 ⇒ 9 | 18 ⇒ free | 19 ⇒ free
4 ⇒ In use | 5 ⇒ In use | 6 ⇒ In use | 7 ⇒ In use
8 ⇒ In use | 9 ⇒ 00000011 | 10 ⇒ 00000000 | 11 ⇒ 00000000
12 ⇒ 00000000 | 13 ⇒ 00000000 | 14 ⇒ 00000000 | 15 ⇒ 00000000
16 ⇒ 00000000 | 17 ⇒ 9 | 18 ⇒ free | 19 ⇒ free
In this case the memory address #17 is calling the value saved in memory address #9 which is 00000011 and with this we’re saving memory slots and re-using past data to retrieve even faster.
In computer science, a pointer is an object in many programming languages that stores a memory address. This can be that of another value located in computer memory, or in some cases, that of memory-mapped computer hardware.
A pointer references a location in memory, and obtaining the value stored at that location is known as dereferencing the pointer. The actual format and content of a pointer variable is dependent on the underlying computer architecture. More info here
Run out of memory
As we’ve seen in this post the memory slots are something finite, that means you can run out of memory (probably you’ve lived it in the past). The memory allocation is something we’ve to understand for this very same reason. The question now is how to measure these things in our algorithms directly? The answer is given by the BigO Notation and is something we’ll see in the next blog post
I hope you learnt a lot with this one
Thanks for reading
DanielM